
Big data yêu cầu một bộ công cụ và kỹ thuật đặc biệt để xử lý đống dữ liệu khổng lồ và có một số công cụ khá nổi tiếng ngoài thị trường như Hadoop (hỗ trợ lưu trữ và xử lý big data), Spark (giúp tính toán dữ liệu ngay trong bộ nhớ), Storm, MongoDB… Mỗi công cụ lại có tác dụng và chức năng khác nhau để hỗ trợ phân tích big data.
Trong mọi lĩnh vực đều có một yếu tố quan trọng nhất giúp bạn dễ dàng làm chủ và tiến xa hơn. Với lĩnh vực big data, câu trả lời là: Bạn cần có một bộ công cụ big data tốt.
Phân tích và xử lý big data không phải là một nhiệm vụ dễ dàng. Ngay như trong cái tên của nó, big data tức là dữ liệu lớn, tất nhiên để làm việc và giải quyết nó cũng là một vấn đề lớn. Bạn cần phải có một bộ công cụ tuyệt vời không chỉ giải quyết vấn đề mà còn giúp bạn tạo ra những kết quả có ích.
Danh sách công cụ phân tích dữ liệu big data tốt nhất
Dưới đây là danh sách 5 công cụ big data tốt nhất:
- Apache Hadoop
- Datawrapper
- Apache Cassandra
- MongoDB
- RapidMiner
Big data là một phần không thể thiếu của mọi công ty, tổ chức hiện nay. Các công ty như Google, Facebook, Apple… luôn sử dụng big data là công cụ hữu hiệu để training AI, phân tích xu hướng thị thường để dự đoán xu hướng, thiết kế sản phẩm…
Có một số yếu tố mà bạn cần phải lưu tâm khi lựa chọn công cụ. Đó là kích thước big data, chi phí mua công cụ, loại phân tích mà bạn muốn.v.v…
Ngày nay, với tốc độ tăng trưởng cấp số nhân của big data, thị trường cũng tràn ngập các thể loại công cụ big data, đủ loại “thượng vàng hạ cám”. Do đó, để giúp bạn không bị choáng ngợt và tối ưu hóa chi phí và hiệu quả công việc. Chúng ta sẽ cùng nhau xem danh sách 10 công cụ big data tốt nhất dưới đây.
1. Apache Hadoop
Đứng đầu trong danh sách này không ai khác, chính là Hadoop. Apache Hadoop là một trong những công cụ được sử dụng phổ biến nhất trong lĩnh vực big data. Hadoop là một open-source framework từ Apache. Hadoop được dùng để lưu trữ và phân tích các tập dữ liệu lớn.
Hadoop được viết bằng Java ứng dụng công nghệ MapReduce. Hiểu nôm na là công nghệ phân tán dữ liệu do Google phát triển. Tức là từ dữ liệu lớn, chúng sẽ được tách ra thành nhiều dữ liệu nhỏ hơn và sắp xếp chúng lại để dễ dàng truy xuất hơn. Bạn có thể hình dung rõ nét qua các kết quả tìm kiếm của Google. Bạn thử tìm kiếm với một từ khóa nào đó nhưng ở nhiều khu vực khác nhau: Google.com. Google.com.vn, Google.in… chắc chắn kết quả tìm kiếm sẽ khác nhau đôi chút.
Hadoop sử dụng kiến trúc clustered. Một Cluster là một nhóm các hệ thống được kết nối qua LAN. Hadoop cho phép xử lý dữ liệu song song vì nó hoạt động đồng thời trên nhiều máy.
Hadoop gồm 3 layer chính:
- Hadoop Distributed File System (HDFS): Là hệ thống file phân tán cung cấp truy cập thông lượng cao cho ứng dụng khai thác dữ liệu.
- Map-Reduce: Đây là hệ thống dựa trên YARN dùng để xử lý song song các tập dữ liệu lớn. YARN: layer quản lý tiến trình và tài nguyên của các cluster.
Để dễ hình dung hơn cơ chế và kiến trúc của Hadoop, mời bạn tham khảo hình bên dưới đây:
Chức năng chính của Hadoop:
- Lưu trữ và xử lý những dữ liệu lớn, lên tới Petabyte (khoảng 1 triệu GB).
- Xử lý trong môi trường phân tán, dữ liệu được lưu ở nhiều nơi khác nhau nhưng yêu cầu xử lý đồng bộ.
2. Cassandra
Apache Cassandra là hệ quản trị cơ sở liệu NoSQL phân tán mã nguồn mở. Công cụ được xây dựng để quản lý khối lượng dữ liệu khổng lồ trải rộng trên nhiều máy chủ, đảm bảo tính sẵn sàng cao.

Cassandra sử dụng CQL (Cassandra Structure Language) để tương tác với cơ sở dữ liệu.
Một số công ty sử dụng Cassandra như: Accenture, American Express, Facebook, General Electric, Honeywell, Yahoo,.v.v…
Ưu điểm của Cassandra:
- Tốc độ xử lý rất nhanh
- Lưu log có kiến trúc giúp việc debug, phát hiện lỗi tốt hơn
- Khả năng mở rộng tự động
- Mở rộng hệ thống theo tuyến tính.
Nhược điểm:
- Yêu cầu trình độ nhất định để khắc phục khi có vấn đề phát sinh
- Thiếu tính năng Row-level locking
- Clustering còn chưa hiệu quả, cần cải thiện để có hiệu quả hơn
3. Datawrapper
Datawrapper là một platform mã nguồn mở có chức năng chính là trực quan hóa dữ liệu, hỗ trợ người dùng tạo các biểu đồ đơn giản, chính xác, thân thiện và có thể nhúng vào website dễ dàng.
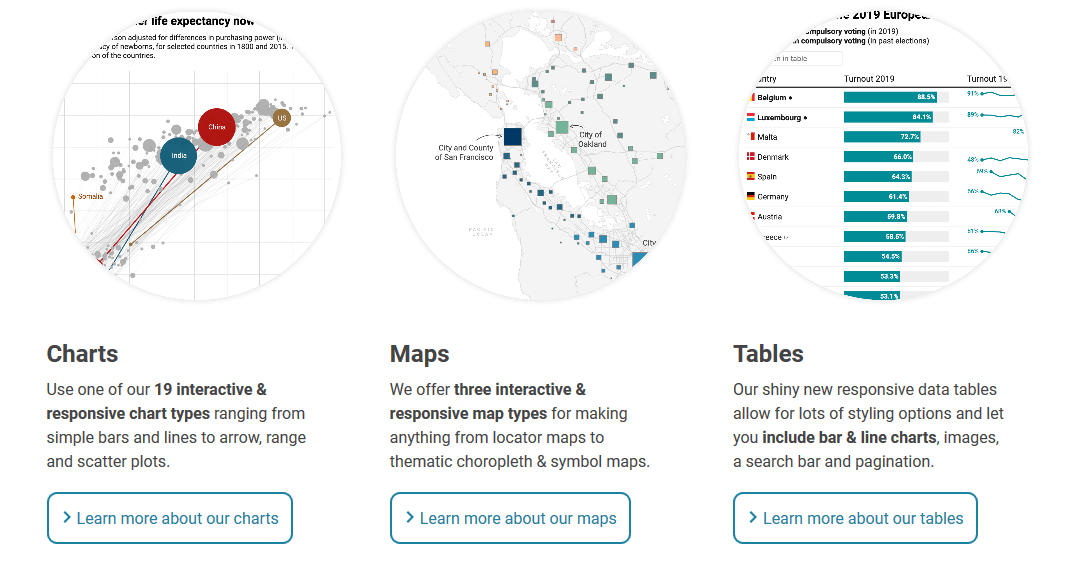
Chức năng chính của Datawrapper
Các công ty sử dụng phần mềm này chủ yếu là các tòa soạn báo, có thể kể một số tên tuổi đình đám như: The Times, Fortune, Mother Jones, Bloomberg, Twitter,.v.v…
Ưu điểm:
- Thân thiện với mọi loại thiết bị, kể cả thiết bị di động, máy tính để bàn…
- Fully responsive
- Tốc độ cho kết quả nhanh
- Nhiều tùy chọn để tùy biến
- Không yêu cầu người dùng phải biết lập trình
Nhược điểm:
- Bảng màu còn hạn chế
- Mất phí
4. MongoDB
MongoDB là một NoSQL, một kiểu hệ quản trị cơ sở dữ liệu hướng document, được viết bằng C/C++ và Javascript. MongoDB được cung cấp miễn phí và là một công cụ mã nguồn mở hỗ trợ đa nền tảng gồm: Window, Linux…
Đây là công cụ quản trị cơ sở dữ liệu phổ biến nhất cho big data, vì nó hỗ trợ rất tốt cho việc quản lý dữ liệu không có cấu trúc hay loại dữ liệu thay đổi thường xuyên.
MongoDB sử dụng dynamic schemas, do đó, bạn có thể chuẩn bị và tạo dữ liệu một cách nhanh chóng, không cần phải thiết kế cấu trúc trước cho dữ liệu, thích thì thêm vào DB thôi.
Chức năng chính của MongoDB gồm có: Aggregation, Ad Hoc-queries, Uses BSON format, Sharding, Indexing, Replication, Server-side execution of javascript, Schemaless, Capped collection, MongoDB management service (MMS)…
Các công ty sử dụng MongoDB gồm có: Facebook, eBay, MetLife, Google,v.v…
Ưu điểm:
- Học và tiếp cận rất dễ
- Hỗ trợ nhiều công nghệ và nền tảng khác nhau
- Dễ cài đặt và bảo trì
- Đáng tin cậy và chi phí thấp
Nhược điểm:
- Số liệu phân tích còn hạn chế
- Một số trường hợp báo cáo tốc độ ứng dụng chậm đi khi sử dụng MongoDB
5. RapidMiner
Rapidminer là một công cụ đa nền tảng cung cấp môi trường tích hợp cho khoa học dữ liệu, machine learning, và phân tích dự đoán số liệu. Rapidminer cung cấp nhiều loại giấy phép tùy vào từng loại quy mô công ty, quy mô dữ liệu.
Ngoài ra, Rapidminer cũng có một phiên bản miễn phí phục vụ cho mục đích học tập với giới hạn 1 CPU và 10,000 records.
Các công ty đang sử dụng RapidMiner: Hitachi, BMW, Samsung, Airbus…
Ưu điểm:
- Open-source Java core
- Có nhiều công cụ và thuật toán cao cấp phục vụ rất tốt nhu cầu phân tích dữ liệu big data.
- Có GUI
- Dễ dàng tích hợp các API hay cloud.
- Dịch vụ chăm sóc khách hàng rất tốt
Nhược điểm
- Các dịch vụ online cần cải thiện
Thay lời kết
Qua bài viết này, mình đã giới thiệu một số công cụ tốt nhất phục vụ cho nhu cầu lưu trữ và phân tích dữ liệu big data. Trong số các công cụ này, có công cụ miễn phí, có công cụ phải trả phí.
Tùy thuộc vào nhu cầu công việc, quy mô dữ liệu mà bạn lựa chọn công cụ big data phù hợp nhất.
Hi vọng các bạn sẽ ủng hộ các bài viết về Big data, hẹn gặp lại các bạn ở bài viết sau.
Theo vntalking.com
Japan IT Works
