
Redis là gì?
Ngày nay, khái niệm NoSQL trở nên không còn xa lạ trong giới Công Nghệ Thông Tin (CNTT). Đi kèm với đó là sự ra đời của hàng loạt hệ quản trị cơ sở dữ liệu (DBMS) phát triển dựa trên đặc thù của NoSQL: Non-relational (không quan hệ), Distributed (phân tán), Open-source (mã nguồn mở), Horizontally scalable (dễ dàng mở rộng theo chiều ngang).
Redis là cơ sở dữ liệu mang phong cách NoSQL, lưu trữ dữ liệu với dạng KEY-VALUE với nhiều tính năng được sử dụng rộng rãi. Nó có thể hỗ trợ nhiều kiểu dữ liệu như: strings, hashes, lists, sets, sorted. Đồng thời có thể cho phép scripting bằng ngôn ngữ Lua.
NoSQL là một khái niệm chỉ về một lớp các hệ cơ sở dữ liệu không sử dụng mô hình quan hệ (RDBMS). RDBMS vốn tồn tại khá nhiều nhược điểm như có hiệu năng không tốt nếu kết nối dữ liệu nhiều bảng lại hay khi dữ liệu trong một bảng là rất lớn.
Thuật ngữ NoSQL đánh dấu bước phát triển của thế hệ CSDL mới: phân tán (distributed) + không ràng buộc (non-relational).
Đặc trưng cơ bản của Redis
1. Data model
Khác với RDMS như MySQL, hay PostgreSQL, Redis không có bảng. Redis lưu trữ data dưới dạng key-value. Thực tế thì memcache cũng làm vậy, nhưng kiểu dữ liệu của memcache bị hạn chế, không đa dạng được như Redis, do đó không hỗ trợ được nhiều thao tác từ phía người dùng. Dưới đây là sơ lược về các kiểu dữ liệu Redis dùng để lưu value.
- STRING: Có thể là string, integer hoặc float. Redis có thể làm việc với cả string, từng phần của string, cũng như tăng/giảm giá trị của integer, float.
- LIST: Danh sách liên kết của các strings. Redis hỗ trợ các thao tác push, pop từ cả 2 phía của list, trim dựa theo offset, đọc 1 hoặc nhiều items của list, tìm kiếm và xóa giá trị.
- SET Tập hợp các string (không được sắp xếp). Redis hỗ trợ các thao tác thêm, đọc, xóa từng phần tử, kiểm tra sự xuất hiện của phần tử trong tập hợp. Ngoài ra Redis còn hỗ trợ các phép toán tập hợp, gồm intersect/union/difference.
- HASH: Lưu trữ hash table của các cặp key-value, trong đó key được sắp xếp ngẫu nhiên, không theo thứ tự nào cả. Redis hỗ trợ các thao tác thêm, đọc, xóa từng phần tử, cũng như đọc tất cả giá trị.
- ZSET (sorted set): Là 1 danh sách, trong đó mỗi phần tử là map của 1 string (member) và 1 floating-point number (score), danh sách được sắp xếp theo score này. Redis hỗ trợ thao tác thêm, đọc, xóa từng phần tử, lấy ra các phần tử dựa theo range của score hoặc của string.
Lưu ý nhỏ:
Trang web ktmt.github.io đưa ra loạt bài phân tích về source code Redis (viết bằng C), trong đó có 1 phần về kiểu dữ liệu của Redis. Tham khảo các bài viết đó, chúng ta có thể thấy Redis sử dụng 1 layer mô tả dữ liệu ở mức độ abstract, là redisObjectr-robj (định nghĩa trong redis.h), các thao tác cơ bản của db (db.c) đều làm việc trực tiếp với robj và không cần biết đến sự tồn tại của các kiểu string, list, hash, set, zset. Sơ đồ tổ chức có thể tham khảo trong mô hình dưới đây.
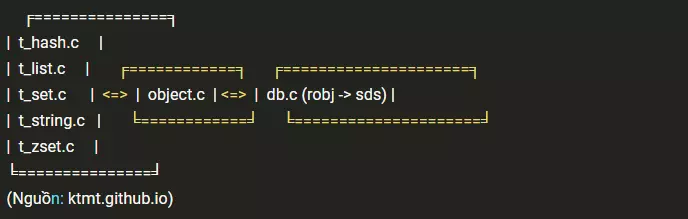
Thiết kế này giúp thao tác làm việc với các kiểu dữ liệu khác nhau trở nên dễ dàng quản lý hơn, đồng thời hỗ trợ việc tăng cường số lượng kiểu dữ liệu trong tương lai
2. Master/Slave Replication
Đây không phải là đặc trưng quá nổi bật, các DBMS khác đều có tính năng này, tuy nhiên chúng ta nêu ra ở đây để nhắc nhở rằng, Redis không kém cạnh các DBMS về tình năng Replication.
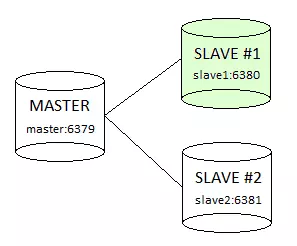
3. In-memory
Không như các DBMS khác lưu trữ dữ liệu trên đĩa cứng, Redis lưu trữ dữ liệu trên RAM, và đương nhiên là thao tác đọc/ghi trên RAM. Với người làm CNTT bình thường, ai cũng hiểu thao tác trên RAM nhanh hơn nhiều so với trên ổ cứng, nhưng chắc chắn chúng ta sẽ có cùng câu hỏi: Điều gì xảy ra với data của chúng ta khi server bị tắt?
Rõ ràng là toàn bộ dữ liệu trên RAM sẽ bị mất khi tắt server, vậy làm thế nào để Redis bảo toàn data và vẫn duy trì được ưu thế xử lý dữ liệu trên RAM. Chúng ta sẽ cùng tìm hiểu về cơ chế lưu dữ liệu trên ổ cứng của Redis trong phần tiếp theo của bài viết.
4. Persistent redis
Dù làm việc với data dạng key-value lưu trữ trên RAM, Redis vẫn cần lưu trữ dữ liệu trên ổ cứng. 1 là để đảm bảo toàn vẹn dữ liệu khi có sự cố xảy ra (server bị tắt nguồn) cũng như tái tạo lại dataset khi restart server, 2 là để gửi data đến các slave server, phục vụ cho tính năng replication. Redis cung cấp 2 phương thức chính cho việc sao lưu dữ liệu ra ổ cứng, đó là RDB và AOF. RDB (Redis DataBase file)
Cách thức làm việc
RDB thực hiện tạo và sao lưu snapshot của DB vào ổ cứng sau mỗi khoảng thời gian nhất định.
Ưu điểm
- RDB cho phép người dùng lưu các version khác nhau của DB, rất thuận tiện khi có sự cố xảy ra.
- Bằng việc lưu trữ data vào 1 file cố định, người dùng có thể dễ dàng chuyển data đến các data centers khác nhau, hoặc chuyển đến lưu trữ trên Amazon S3.
- RDB giúp tối ưu hóa hiệu năng của Redis. Tiến trình Redis chính sẽ chỉ làm các công việc trên RAM, bao gồm các thao tác cơ bản được yêu cầu từ phía client như thêm/đọc/xóa, trong khi đó 1 tiến trình con sẽ đảm nhiệm các thao tác disk I/O. Cách tổ chức này giúp tối đa hiệu năng của Redis. Khi restart server, dùng RDB làm việc với lượng data lớn sẽ có tốc độ cao hơn là dùng AOF.
Nhược điểm
- RDB không phải là lựa chọn tốt nếu bạn muốn giảm thiểu tối đa nguy cơ mất mát dữ liệu. Thông thường người dùng sẽ set up để tạo RDB snapshot 5 phút 1 lần (hoặc nhiều hơn). Do vậy, trong trường hợp có sự cố, Redis không thể hoạt động, dữ liệu trong những phút cuối sẽ bị mất.
- RDB cần dùng fork() để tạo tiến trình con phục vụ cho thao tác disk I/O. Trong trường hợp dữ liệu quá lớn, quá trình fork() có thể tốn thời gian và server sẽ không thể đáp ứng được request từ client trong vài milisecond hoặc thậm chí là 1 second tùy thuộc vào lượng data và hiệu năng CPU.
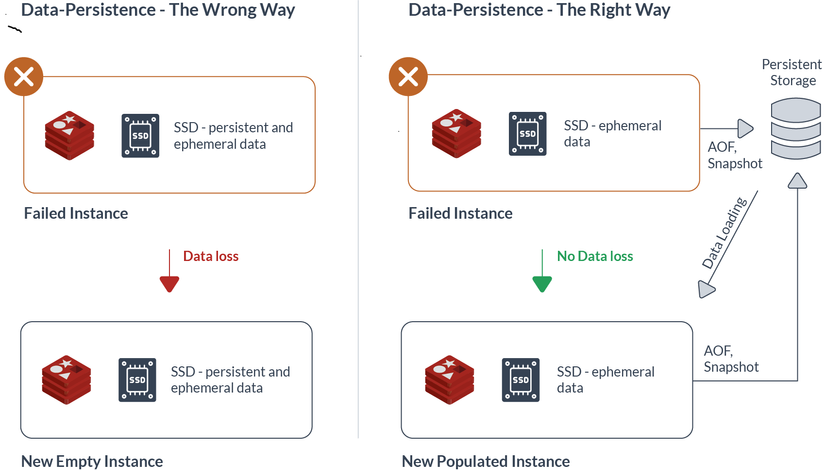
Như minh họa ở trên, trong trường hợp không có bản sao của tập dữ liệu còn lại trong RAM, Redis Enterprise sẽ tìm bản sao cuối cùng của tập dữ liệu trong các thiết bị được kết nối mạng được kết nối với nút không thành công và sử dụng nó để điền phân đoạn Redis trên phiên bản đám mây mới.
AOF (Append Only File)
Cách thức làm việc:
AOF lưu lại tất cả các thao tác write mà server nhận được, các thao tác này sẽ được chạy lại khi restart server hoặc tái thiết lập dataset ban đầu.
Ưu điểm
- Sử dụng AOF sẽ giúp đảm bảo dataset được bền vững hơn so với dùng RDB. Người dùng có thể config để Redis ghi log theo từng câu query hoặc mỗi giây 1 lần.
- Redis ghi log AOF theo kiểu thêm vào cuối file sẵn có, do đó tiến trình seek trên file có sẵn là không cần thiết. Ngoài ra, kể cả khi chỉ 1 nửa câu lệnh được ghi trong file log (có thể do ổ đĩa bị full), Redis vẫn có cơ chế quản lý và sửa chữa lối đó (redis-check-aof).
- Redis cung cấp tiến trình chạy nền, cho phép ghi lại file AOF khi dung lượng file quá lớn. Trong khi server vẫn thực hiện thao tác trên file cũ, 1 file hoàn toàn mới được tạo ra với số lượng tối thiểu operation phục vụ cho việc tạo dataset hiện tại. Và 1 khi file mới được ghi xong, Redis sẽ chuyển sang thực hiện thao tác ghi log trên file mới.
Nhược điểm
- File AOF thường lớn hơn file RDB với cùng 1 dataset.
- AOF có thể chậm hơn RDB tùy theo cách thức thiết lập khoảng thời gian cho việc sao lưu vào ổ cứng. Tuy nhiên, nếu thiết lập log 1 giây 1 lần có thể đạt hiệu năng tương đương với RDB.
- Developer của Redis đã từng gặp phải bug với AOF (mặc dù là rất hiếm), đó là lỗi AOF không thể tái tạo lại chính xác dataset khi restart Redis. Lỗi này chưa gặp phải khi làm việc với RDB bao giờ.
- Câu hỏi đặt ra là, chúng ta nên dùng RDB hay AOF? Mỗi phương thức đều có ưu/nhược điểm riêng, và có lẽ cần nhiều thời gian làm việc với Redis cũng như tùy theo ứng dụng mà đưa ra lựa chọn thích hợp. Nhiều người chọn AOF bới nó đảm bảo toàn vẹn dữ liệu rất tốt, nhưng Redis developer lại khuyến cáo nên dùng cả RDB, bởi nó rất thuận tiện cho việc backup database, tăng tốc độ cho quá trình restart cũng như tránh được bug của AOF.
- Cũng cần lưu ý thêm rằng, Redis cho phép không sử dụng tính năng lưu trữ thông tin trong ổ cứng (không RDB, không AOF), đồng thời cũng cho phép dùng cả 2 tính năng này trên cùng 1 instance. Tuy nhiên khi restart server, Redis sẽ dùng AOF cho việc tái tạo dataset ban đầu, bới AOF sẽ đảm bảo không bị mất mát dữ liệu tốt hơn là RDB.
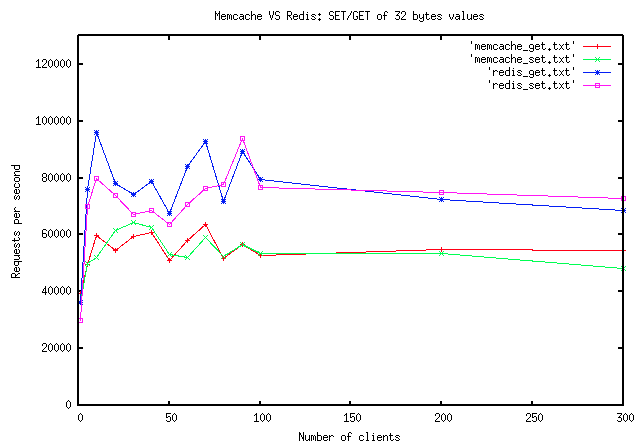
5. Redis vs Memcached
Số lượng clients tăng thì tốc độ của Redis tỏ ra nhanh hơn.
Japan IT Works sưu tầm
